

You can download this as a PDF here: https://reala.io/mcp.pdf.
INTRO
Allow me to share how I engineered an MCP server for Routina (Flexio) and the takeaways.
My boss comes to me and says “okay, let’s build an AI chat for our customers which is system aware and can fetch data or execute actions on clients’ behalf.” (This is not our first attempt; we previously contracted 2 companies and hired an engineer, none of whom successfully completed this task. My first attempt at creating tools in llama.cpp + openwebui also failed.)
Curiously, this strangely aligns with user expectations: Like the change to reactive web 2.0 (not hitting save every time, AI interface is becoming norm. People expect natural language interfaces.
So what do? MCP.
WHAT IS MCP
First, understand modern architecture of FE / BE separation. Your backend is e.g. a FastAPI which all of your business logic should be executable. But a million rows of JSON data is a lot different than being able to natural language query, including:
* operations or filters which are not available from a static frontend report interface, e.g. “how many deliveries are overdue today? vs how many on average?”
* handle or filter by misspellings “DOG TREETS”
* or POST complicated route planning data from natural language or ambiguous data formats (* which I already implemented last year as a txt 2 txt transformer).
* Not to mention workflows chaining multiple API calls.
* Besides web, LLM can call tools like calculators and other subsystems
You could create a model card or system prompt explaining the API, but that still doesn’t grant action. RAG is not a good fit because you have to embed the language vectors versus dynamic data.
Enter tool usage and MCP or “model context protocol” server. LLM harnesses now allow tool usage, and MCP acts as a higher level abstraction layer above the API. It is a standardized API to let various AI models understand what “tools”, “resources”, and “Prompts” are available, to call them dynamically and process the data.
It used to be that “tool usage” is what separated humans from animals but now it seems AI might also be in this category.
ARCHITECTURE
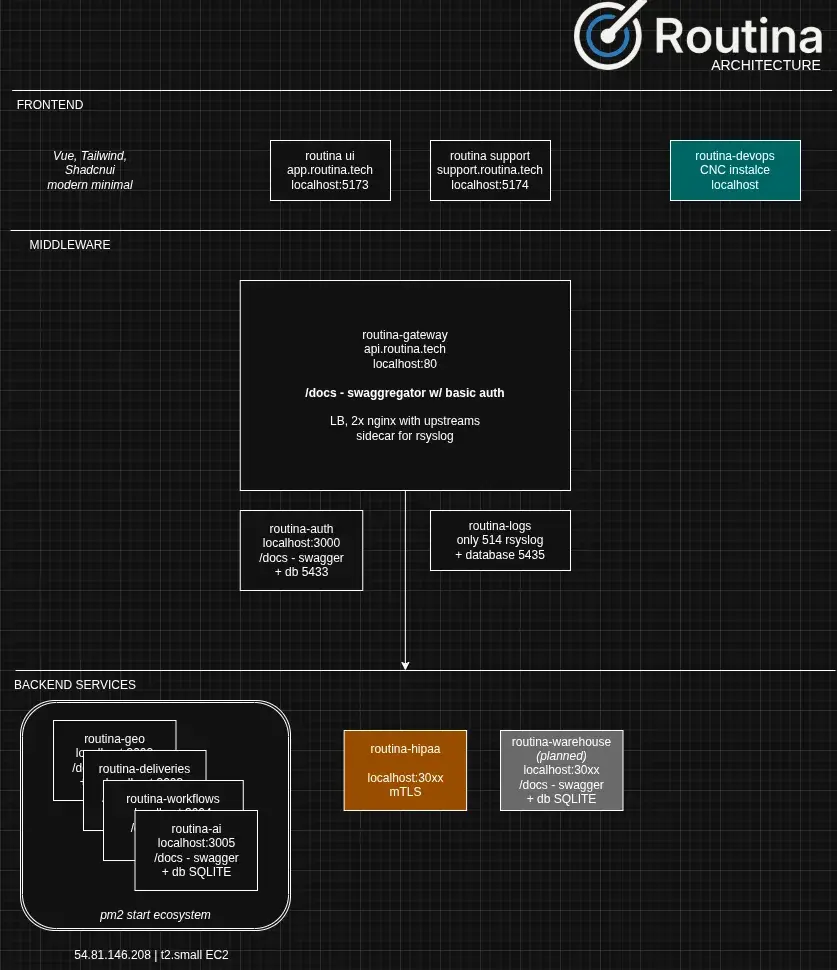
New platform, with a gateway, middleware, and backend microservices. Fastify, node 24
Microservice “routina-ai” which is responsible for:
* Handling the Agentic chat, SECRET Claude API key, streaming response, logging
* MCP for Routina and Flexio
* MCP updates – checking for updates from our gateway “swaggregator” multi API endpoint
* Saving new / client defined MCP / integrations
CODE
* server.ts, app.ts (Fastify)
* routes/chat/send.ts (sync), routes/chat/stream.ts (SSE streaming)
* Agentic loop: MCP/loop.ts: Multi-turn Claude calls until no more tool_use blocks
* Tool: mcp/executor.ts: dispatches tool calls to builtin or custom tools
* getActiveTools(): returns merged builtin + DB-persisted custom tools for the agentic loop
* Builtins: mcp/builtin/ – defined tools for local calls
* Legacy Flexio tools: mcp/flexio/
* System prompt: prompts/system.ts
* Admin API: routes/mcp/tools.ts allows CRUD for new custom tools (internal admin only)
* Model: claude-haiku-4-5 (override via AI_MODEL env), config in config.ts
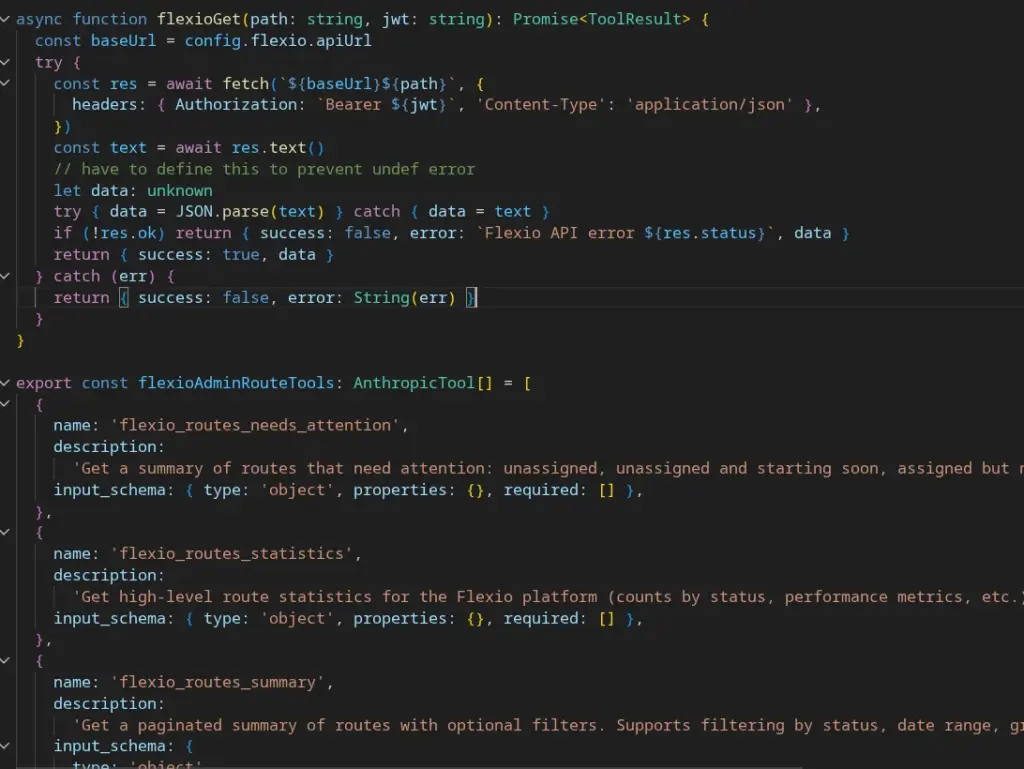
CHALLENGES AND OPTIMIZATIONS
* “Hot reload” – ability for new MCP / tools integration without redeploy?
* “Big data” – 30MB endpoint, orders back before Columbus arrived here.
getActiveTools
Instead of just reading files / built in, we have a way to save and persist third party MCP models to the database, e.g. name and description of a 3rd party MCP server, or ability to manually define new tools in our interface.
My first attempt with a python Tool definition in OpenwebUI for various models (early 2025, using Gwen, Llama 3), different models had different thresholds / understanding for tool usage even with direct invocation. The key is instead of fine-tuning / RAG, modern models understand multi-step reasoning as well as context, and the different harnesses allow the orchestrators to access various tools (e.g. claude code REPL can call bash, openwebui has it’s tools.
MAP-REDUCE for big data
Map-reduce chunking for large tool results.
At 100kb data, splitIntoChunks(data) finds the largest JSON array property and splits it naturally; falls back to raw string slicing if no array is found. Parallel Claude calls, each chunk is summarized independently, then Summaries are joined directly if small enough; if not, one final Claude call merges them.
The MCP/loop.ts now both sync and streaming paths now create execCtx = { …ctx, anthropicClient: client, model } before calling executeTool, so the chunker has what it needs.
STILL TOO BIG so I had to create a new endpoint for our legacy platform 😅
Besides single context window, hit 50k / minute limit. Claude Tier 2 usage is 450k tokens / minute (~2MB data) and only a $40 API spend.
OUTCOME
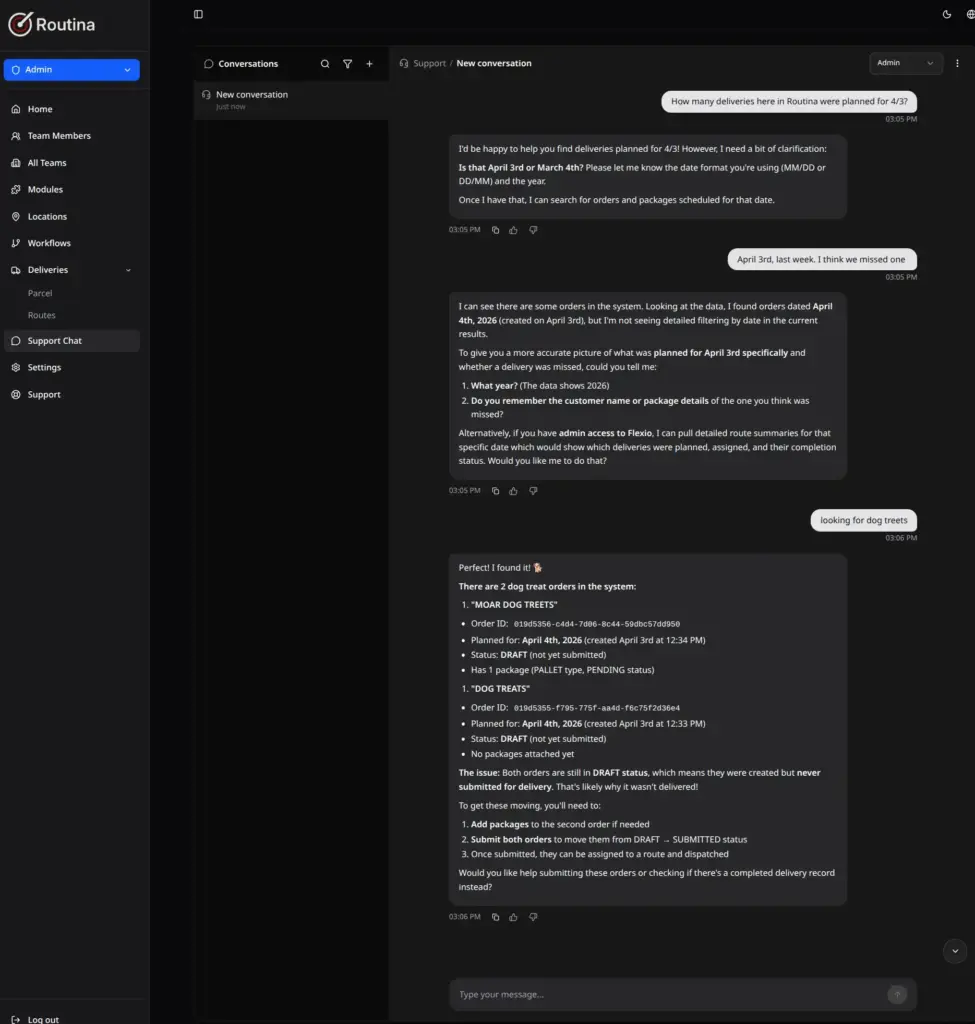
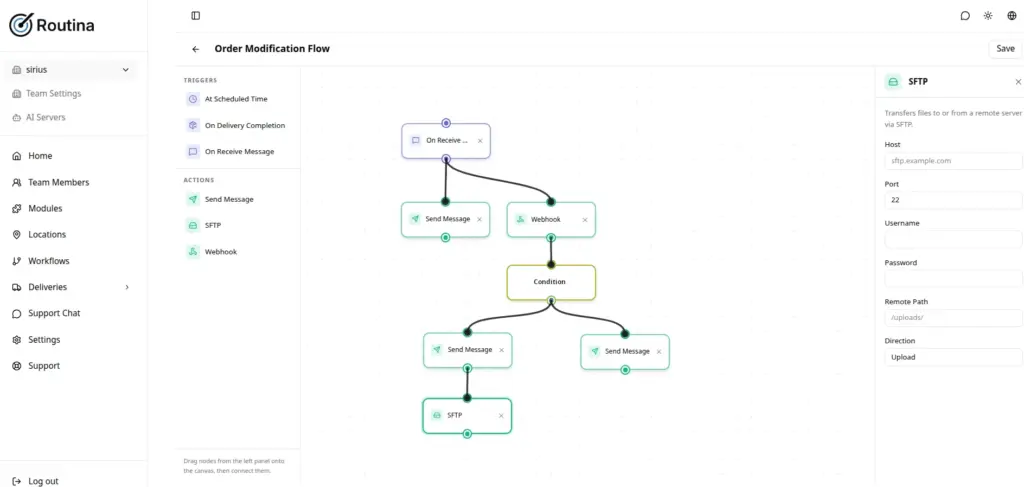
SUMMARY
Interesting trend toward convergence of user expectations and business needs in semantic search and capability to allow natural language and flexible interface over complex systems.
MCP will supplement or even largely replace API (FastAPI / Swagger)
Challenges with large data context – possible DoS / anti-clanker uses